How is Textractor Helpful in Document Parsing
In today's fast-paced business environment, document management remains a critical yet time-consuming task. Office workers spend a significant portion of their work hours manually filing and extracting information from documents. This manual process not only consumes valuable time but also incurs substantial costs and is prone to errors. To address these challenges, automation solutions have become increasingly essential. Textractor, an AI-based document parsing tool, aims to revolutionize the way organizations handle document management by automating the extraction and classification of information from various types of documents.
Problem Statement
Manual document management is a major bottleneck in many organizations. Office workers spend between 40–60% of their working hours on tasks such as filing and extracting information from documents. This inefficient process leads to high salary costs, accounting for 20–45% of overall expenses, and impacts company revenue by 12–15%. Moreover, manual extraction of information is unreliable and highly susceptible to errors. The need for a more efficient, accurate, and cost-effective solution is evident, particularly in sectors dealing with large volumes of legal documents where precision and speed are paramount.
Project Overview
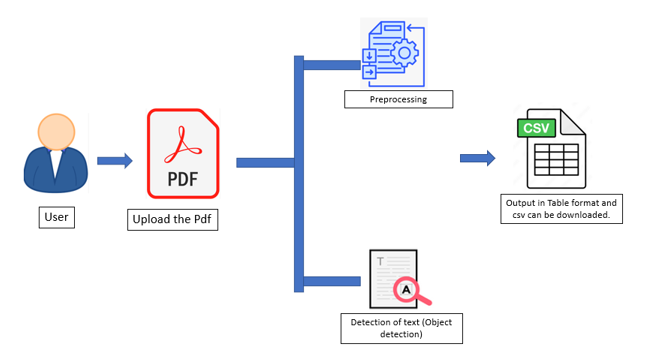
Textractor is designed to address the inefficiencies and errors associated with manual document management. Leveraging advanced AI algorithms, Textractor automates the detection and extraction of multiple objects and patterns from documents, particularly legal documents. The tool is built on several fundamental pillars:
- Pattern Extraction: Identifies relevant patterns and filters out irrelevant data within PDF documents.
- Object Detection: Uses deep learning models to classify key features from images—like judge names or case numbers.
- No Manual Efforts: Fully automated, ensuring accuracy and eliminating manual errors.
- Intelligent Text Extraction: Custom algorithms extract text accurately after classification.
- Speed: Reduces total document processing time by up to 80%.
- Structured Information: Converts extracted text into structured tables for easy analysis.
Benefits
- Significant Time Savings – Reduces document management time by 80%.
- Cost Efficiency – Cuts operational expenses by reducing manual effort.
- High Accuracy – AI-based extraction minimizes errors for reliable outcomes.
- Enhanced Data Processing – Structured outputs simplify downstream workflows.
- Scalability – Handles large document volumes with ease.
- Improved Decision-Making – Enables faster, data-driven decisions.
Achievements
- Successful Implementation in Legal Sector – Streamlined causelist processing by accurately extracting judge names, parties, and case numbers.
- User Adoption – Received excellent feedback for usability and workflow improvement.
- Continuous Improvement – Regular updates leveraging user feedback and AI advancements.
Conclusion
Textractor represents a major advancement in document management, automating the extraction and classification of information across diverse document types. By reducing costs, time, and manual errors, Textractor enhances productivity and reliability in enterprise workflows. Its structured, accurate, and fast data extraction capabilities make it an invaluable asset across industries. As Textractor continues to evolve, it will further redefine automation in document management.
Textractor